情報収集ツール紹介:『Wayback Machine』を使おう
編集:ゲイリー・プライス
翻訳:エァクレーレン

この記事はthe Global Investigative Journalism Network (GIJN)によって公開されました。日本語訳はGIJNのご支援のもと報道実務家フォーラムが公開したものです。貴重な情報を提供してくださり心より感謝申し上げます。
This story was originally published by the Global Investigative Journalism Network.
J-Forum publish the Japanese translation with GIJN’s support.
We’re grateful to GIJN for offering and allowing to translate it into Japanese.

著名な図書館司書でコンサルタントでもあるゲイリー・プライスによる、GJINの新たな特集「The Research Desk」をご紹介しよう。Library Journal向けにブログ「INFOdocket」を執筆しているゲイリーが、GIJNの読者に向け、世界中の最新のデータベース、デジタルツール、文書についての記事を提供する。
INFOdocket(@infodocket)を立ち上げる以前、ゲイリーは10年にわたり、ResourceShelf及びDocuTickerの共同創業者兼シニアエディターの座にあった。またAsk.comのオンライン情報サービス担当ディレクターを務め、Search Engine Landの寄稿編集者の他、The Invisible Webの共著者でもある。ではゲイリー、よろしく!
Wayback Machineは、数あるインターネット・アーカイブと呼ばれるサービスの一つであり、調査研究のためにインターネットを使う人にとって最も便利で重要なツールに数えられる。
その理由は何か。
ウェブページのアーカイブとして一般に公開されているものとしては、規模が圧倒的に大きいからだ(2015年1月の時点で、1996年に遡って4350億ページ以上が保存されている)。Wayback Machineがなければ、過去のウェブコンテンツを見つけ、アクセスしようとしてもほとんど不可能になるだろう。ウェブ管理者に連絡を取り、自分が必要としている日付のウェブページのコピーを保存していないか尋ねてみるなら話は別だが。
もちろん、Wayback Machineを使うといっても課題がないわけではない。たとえば、データベース内の素材についてキーワード検索をすることができない、コンテンツを収集・保存するウェブ・クローラーは、毎日、一日中、公開されているページすべてを発見し、訪問を繰り返しているわけではない。
4350億ページを対象にキーワード検索ができれば素晴らしいし、いずれはそうした機能を歓迎するときが来るだろうが、誰であっても、任意の時点のウェブページやPDFをアーカイブするためにWayback Machineを利用することは実は可能だし、非常に簡単である。
言い換えれば、Wayback Machineを使えば、あなた自身が選ぶどんなコンテンツでも、簡単かつ無料でアーカイブしておける、ということだ。それは同時に、このデータベースをより完全なものに近づけることに力を貸すことにもなる。
では、そのやり方を見てみよう。
意のウェブページやPDFを恒久的にアーカイブし、アーカイブされた写しのダイレクトリンクを取得するには、以下の手順で行う。
1.Wayback Machineのホームページ http://web.archive.org にアクセスする。
2.ページの右下方にある「Save Page Now」というボックスを見つける。
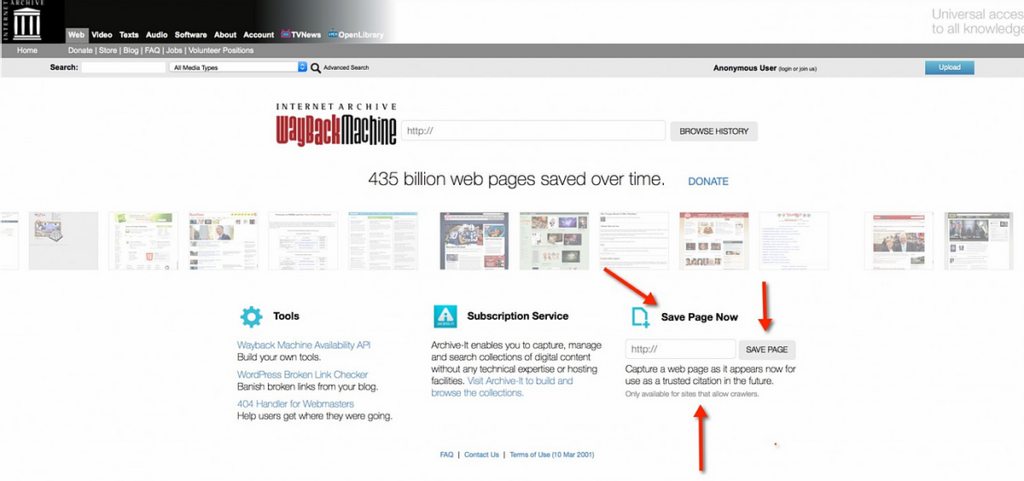
3.ブラウザの別のウィンドウかタブで、アーカイブしたいウェブページやPDFのURLをコピーする。
4.「Save Page Now」のボックスに戻り、URLをペーストし、「save page」をクリックする。これで完了。
5.ほんの数秒で、まさに今アーカイブされたバージョンのウェブページやPDFへのダイレクトリンクを示すボックスが現われる。
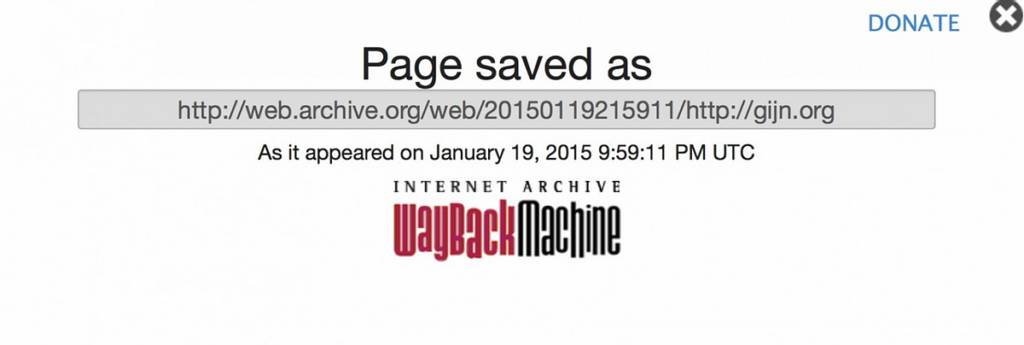
6.Wayback Machine上のこのURLでは、問題のバージョンの日時を、他のバージョン(もしあれば)と共に見ることができる。

もっと簡単な方法
無料で提供されているブックマークレットを使えば、上記のステップを省略することもできる。アーカイブのためのプロセスが、1クリックだけで完了する。ブックマークレットは、ここから入手できる。(※訳注:リンク先は2021年4月14日段階ではアクセスできなかった。今後各自確認をお願いします)
Wayback Machineでアーカイブできないもの
Wayback Machineは[ウェブサイトに設置された]robots.txtに設定された基準を遵守する。ここで除外設定されているページや文書、サーバは巡回対象としない。Wayback Machineに関するFAQ(よくある質問)に詳しい説明がある。また、ウェブページがアーカイブされない原因となりうる問題は、javascriptやパスワードで保護されたページなど、他にもたくさんある。そのいくつかは、ここで詳しく説明されている。
今後の記事で、ウェブアーカイブのための他のツールやサービス、戦略について紹介していこう。
おまけ! Wayback MachineのURLを読み解く方法
Wayback MachineのURLはすべて、ページを巡回・収集・アーカイブした日付と正確な時刻(秒単位まで)が含まれている。
上記の例でアーカイブしたページのURLを分解してみよう。
- http://web.archive.org/web/20150119215911/http://gijn.org
- 2015 →年
- 01 →月
- 19 →日
- 21:59:11 →ページを巡回・アーカイブした時刻。Wayback Machineは時刻にUTCを用いている。
- /GIJN.org →アーカイブされたページ。

ゲイリー・プライス(gprice@mediasourceinc.com)は首都ワシントンD.C.で活動する司書、ライター、コンサルタントで、カンファレンスでの発表も頻繁に行っている。Library Journal向けにブログINFOdocket(@infodocket)を執筆している。ResourceShelf及びDocuTickerの共同創業者でもあった。以前はSearch Engine Landの寄稿編集者、Ask.comでオンライン情報サービス担当ディレクターを務めていた。
原文はこちら:Introducing The Research Desk: Secrets of the Wayback Machine
この翻訳はGoogle News InitiativeとGoogle Asia Pacificの支援を受けて行われました。
This translation is supported by the Google News Initiative and Google Asia Pacific.
Creative Commons Attribution-NonCommercial 4.0 International licence